



As últimas semanas têm sido bem agitadas quando o assunto é a disponibilidade de ferramentas de inteligência artificial no Brasil e no mundo.
Há duas questões importantes sobre isso, e elas estão relacionadas: primeiro, existe um cenário regulatório fragmentado (e fluido) em múltiplos países. Neste momento de transição, as queixas de insegurança jurídica não soam tão exageradas quanto elas costumam soar.
Em segundo lugar, toda empresa tem decisões bastante práticas para tomar na hora de treinar um modelo (e especialmente, a primeira versão do seu primeiro modelo). Quantos idiomas incluir? Quais priorizar? Em qual proporção? Os dados devem incluir linguagens de programação? Quantas? Quais? O modelo terá capacidades matemáticas? E de gerar imagens? E quanto a vídeos? Como garantir a mitigação do mau uso para gerar um vídeo em bengalês com a mesma confiabilidade da mitigação de mau uso em inglês? Aliás, quanto custaria uma multa na Índia? Se deixarmos o bengalês para a segunda versão, quanto podemos economizar com GPUs 1 agora e agilizar o treinamento?
No caso da Apple Intelligence, analisar a combinação entre esses aspectos regulatórios e práticos pode começar a explicar a disponibilidade inicial tão limitada, além de ajudar a estabelecer expectativas realistas para o que virá pela frente.


Primeiro, vale entender a questão global. Nos Estados Unidos, a Apple confirmou recentemente que passará a seguir as diretrizes que o governo dos EUA estabeleceu para o campo da IA. Elas incluem desde o requerimento para que as empresas informem sobre os riscos que o mau uso dos seus sistemas pode oferecer à segurança nacional, até medidas para mitigar a criação e os riscos oferecidos por deep fakes 2.

Apesar de o cumprimento das regras ser voluntário (pelo menos por enquanto), a Amazon, a Anthropic, o Google, a Inflection, a Meta, a Microsoft e a OpenAI já haviam confirmado, na época, que seguiriam o que fosse determinado. Eis que, na última semana, a Apple engrossou a lista.
Enquanto isso, na Europa, o recém-aprovado AI Act entrou em vigor na última quinta-feira. Agora, todos os países-membros do conglomerado têm dois anos para estruturarem a supervisão do cumprimento doméstico das determinações do pacote de leis. Esse pacote prevê regras e restrições que as empresas desenvolvedoras de IA terão que observar, e essas regras e restrições variam de acordo com o tamanho e o risco potencial do modelo.
Por exemplo: IAs que filtram spam são vistas como de “risco mínimo”, e não terão de seguir nenhuma determinação nova. Já IAs como o ChatGPT e DALL·E são vistas como de “risco específico de transparência”, e terão de deixar claro para os usuários que eles estão interagido com máquinas, além de sinalizarem conteúdos sintéticos. IAs como de recrutamento ou de análise de crédito, por sua vez, entram na categoria de “alto risco”, e terão de prestar contas acerca de treinamento e de mitigação de vieses. Por fim, há a categoria de IAs proibidas por oferecerem um “risco inaceitável”. Elas incluem reconhecimento e categorização emocional em ambientes de trabalho, e alguns tipos de coleta e análise biométrica em espaços públicos.

Assim como acontece com qualquer questão regulatória, os dois lados vêm argumentando seus pontos, que não são exatamente novidade para ninguém: enquanto a Europa diz que está tentando proteger a segurança e a privacidade de seus cidadãos, as empresas sujeitas às novas regras se veem limitadas demais, a ponto de retratarem seus negócios como sob ameaça.
A Meta, por exemplo, decidiu recentemente congelar o lançamento de novas funcionalidades de IA na Europa. Isso veio depois de a Comissão de Proteção de Dados da Irlanda ter solicitado à companhia que não use dados de cidadãos europeus para treinar seus modelos. Já a Apple, em resposta ao conjunto de regras estabelecido pela DMA 3, anunciou que não sabe quando disponibilizará a Apple Intelligence no continente.

Já aqui no Brasil, vimos em 2023 praticamente um copiar e colar uma forte inspiração no AI Act europeu para o texto original do PL 4 2.338/2023, que visa regular o desenvolvimento e o uso de inteligência artificial no país. Com mais de 140 emendas propostas ao longo dos últimos oito meses, o PL vive um loop interminável de votações adiadas nas sessões tradicionalmente verborrágicas da Comissão Temporária de Inteligência Artificial do Senado, geralmente elencadas por oficiais perdidamente apaixonados pelo som da própria voz e sem muito interesse em realmente avançar a pauta em questão.

Quem acompanha essas movimentações sabe que não é a primeira vez que o Brasil copia a lição de casa se espelha na Comissão Europeia, na esperança de agilizar a aprovação de um pacote doméstico similar de leis de tecnologia. A LGPD 5 se inspirou tanto na GDPR 6 da Europa que até a tradução do nome é praticamente idêntica. E é justamente a LGPD que vem causando os maiores conflitos com as empresas de tecnologia no Brasil quando o assunto é IA.
No mês passado, seguindo o roteiro da Europa, a Agência Nacional de Proteção de Dados (ANPD) determinou a suspensão da coleta de dados de usuários brasileiros para treinar os sistemas de IA da Meta, com uma multa diária de R$50 mil em caso de descumprimento 7.
Como consequência disso, a Meta suspendeu a disponibilidade das ferramentas de IA generativa que ela já havia liberado no país, como por exemplo a que permitia criar figurinhas no WhatsApp por meio de comandos de texto. Poucos dias depois, ela anunciou a expansão do seu poderoso pacote de ferramentas Meta AI para múltiplos países, além da disponibilidade do modelo Llama 3.1 que traz melhorias significativas em múltiplos aspectos. O Brasil ficou de fora 8.
Para equilibrar um pouco o placar, a Anthropic liberou na última quinta-feira o acesso ao seu (excelente) grande modelo de linguagem Claude no Brasil. Ele já estava disponível no exterior desde março de 2023, e apenas agora chegou por aqui. Perguntada pelo Tecnoblog sobre a relação entre a demora para o lançamento do modelo no Brasil e as adequações à LGPD, a empresa não se manifestou.

De volta à Meta, quem acompanhou o lançamento ou fez testes com a versão 3.0 do modelo Llama, sabe que o desempenho em português era bem ruim. Na verdade, o desempenho em praticamente qualquer idioma que não fosse em inglês era bem ruim, tanto no modelo com 70 bilhões de parâmetros quanto na versão menor, de “apenas” 8 bilhões.
Isso não foi exatamente uma surpresa, já que a própria Meta havia relatado que o Llama 3 havia sido treinado com 95% dos materiais em inglês, e apenas 5% em outros 30 idiomas.
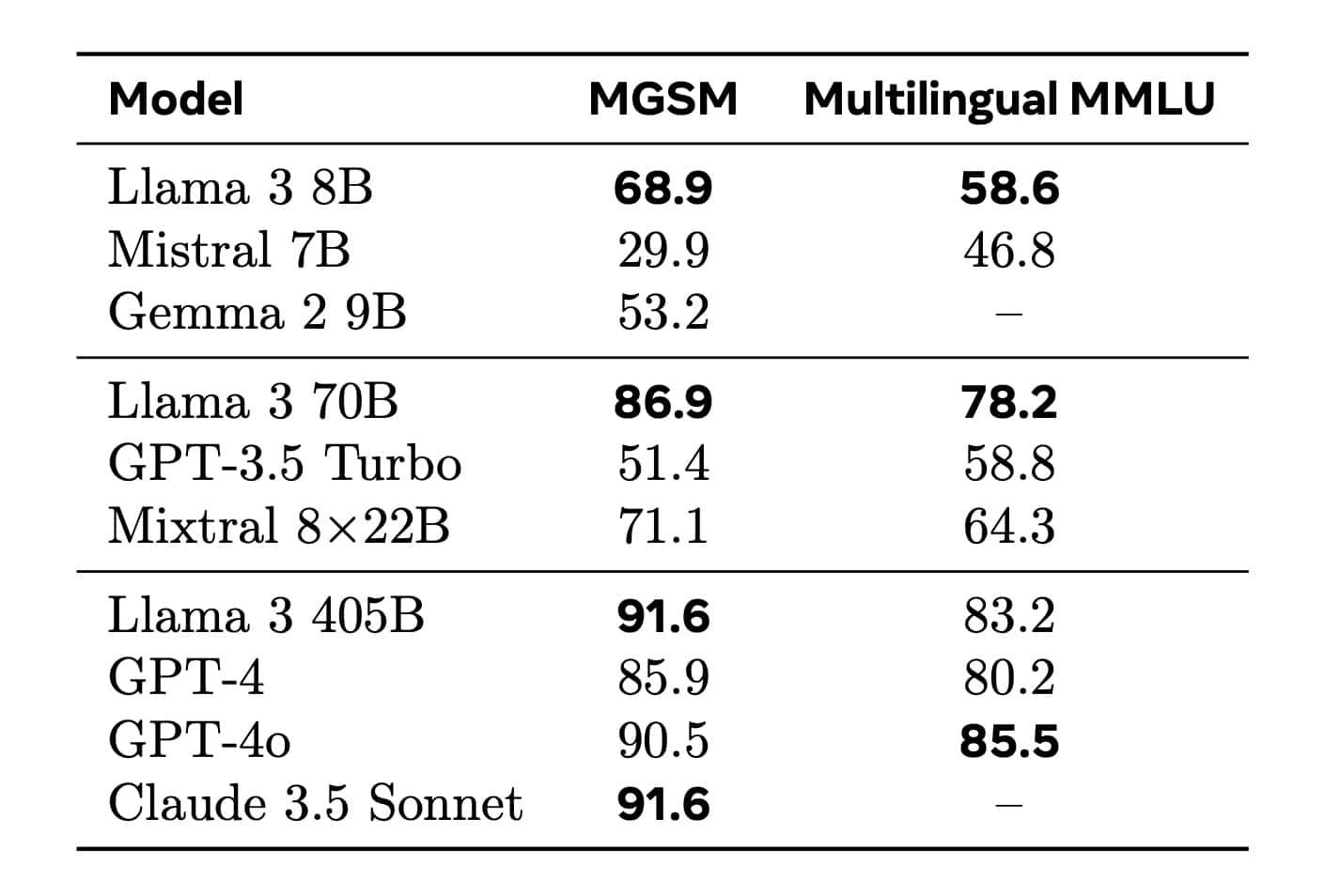
Já para o Llama 3.1, a coisa mudou. No extenso documento técnico [PDF] — que é uma verdadeira aula para quem se interessa pelo assunto —, a Meta detalhou como ela priorizou os aspectos de multilinguagem, com destaque para oito idiomas, incluindo o português. Como resultado, o Llama 3.1 se sai melhor do que modelos equivalentes da Mistral, do Google e da OpenAI nos benchmarks MGSM e Multilingual MMLU 9.
O que nos traz à Apple Intelligence e sua disponibilidade inicial bastante limitada, tanto em questão de territórios quanto de idiomas. No raso documento técnico publicado após a WWDC24, a empresa disse apenas que rodará localmente um modelo com 3 bilhões de parâmetros nos dispositivos compatíveis, e que haverá “um modelo maior” rodando na nuvem. Não há detalhes sobre o tamanho do modelo maior, nem de (ou se) quantos idiomas além do inglês fizeram parte do treinamento.
Seja como for, acho seguro palpitar que, assim como aconteceu com o Llama 3.0, o inglês tenha sido a absoluta (e talvez exclusiva) prioridade, e que mais idiomas devam ser incorporados apenas em versões futuras do modelo. O problema é que isso exigirá basicamente um retreinamento completo, e não apenas uma atualização ou rebalanceamento dos parâmetros, dos neurônios e dos pesos já existentes. Isso demandará mais estrutura, mais tempo, mais dinheiro e beeem mais dados do que para um modelo de 3 bilhões de parâmetros que só fala inglês.
Resumo da ópera
É frustrante que a Apple Intelligence só funcione em inglês? Sim. A Apple opera no mundo todo, mas seu compromisso com o resto do mundo raramente correspondente a essa realidade. É injusto dizer isso por conta da escala em que ela opera? Talvez. Por lado, esse é o trabalho.
De qualquer modo, sendo os EUA o mercado mais importante para a Apple, não é surpresa que isso se reflita na versão preliminar da sua IA. A óbvia familiaridade com o inglês e a falta de regulação para o mercado local viabilizaram não só o treinamento e a disponibilização (relativamente) rápidos da primeira versão da Apple Intelligence, mas também ajustes essenciais nas questões de segurança e confiabilidade, questões essas que ela não podia se dar ao luxo de errar a essa altura do campeonato.
A coisa começa a complicar quando questões regulatórias passam a entrar na lista de custo-benefício na hora de decidir quais países serão os próximos a ganharem uma atenção rentável. Na Europa, eu não tenho dúvidas de que a Apple esteja apenas blefando, e que ela lançará a Apple Intelligence por lá sem grandes problemas uma vez que a próxima versão do modelo conte com suporte a idiomas como alemão, espanhol e francês. Ela está aproveitando esse meio-tempo para dourar a pílula do combate à DMA, já que não teria como oferecer esse tipo de suporte para começo de conversa. É o jogo 10.
Já em relação ao Brasil, precisamos considerar o seguinte: levando em conta um faturamento total de US$383 bilhões em 2023, dos quais US$163 bilhões vieram das Américas, dos quais US$139 bilhões vieram apenas dos EUA, me parece seguro afirmar que nós contribuamos com bem menos de 10% para o faturamento total da empresa. E levando em conta que os dispositivos atualmente compatíveis com a Apple Intelligence estejam alguns graus de magnitude além do orçamento da maioria dos brasileiros, incluindo os que já usam iPhones, iPads e Macs, fica difícil justificar o custo de treinar o modelo para funcionar direito e de forma segura em português, em comparação com o retorno que isso poderia gerar (mesmo levando em conta que isso poderia incentivar mais pessoas a quebrarem o porquinho para comprar dispositivos novos compatíveis).
Felizmente, quem fala ou lida com textos em inglês no dia a dia poderá utilizar a Apple Intelligence, mesmo no Brasil (desde que ajuste algumas configurações do sistema). E o fato de a Apple ter publicado uma página da AI no seu site brasileiro, e o mesmo não acontecer para inúmeros outros países, também pode servir como um fio de esperança aos mais otimistas.
A outra boa notícia é que, quando chegar a hora de treinar a próxima versão da Apple Intelligence em mais idiomas, a coisa deverá se desenrolar relativamente rápido, como foi entre o Llama 3.0 e o Llama 3.1. Aí, só nos restará torcer para que o PL 2.338/2023 não tenha inventado modas demais.


